| 机器学习之线性回归(linear regression) | 您所在的位置:网站首页 › linear regression implementation in python a complete › 机器学习之线性回归(linear regression) |
机器学习之线性回归(linear regression)
|
版权说明 作者:朱涛原文地址:https://github.com/towerjoo/myML/issues/1署名 保持完整性 CC 什么是线性回归?事实上,限于机器学习的年轻(相比于数学,统计学,生物学等),机器学习很多的方法都是来自于其它领域,线性回归也不例外,它是来自于统计学的一个方法。 定义:给定数据集D={(x1, y1), (x2, y2), ... },我们试图从此数据集中学习得到一个线性模型,这个模型尽可能准确地反应x(i)和y(i)的对应关系。这里的线性模型,就是属性(x)的线性组合的函数,可表示为:  向量表示为:  其中,w=(w1; w2;w3; ..., wd) 表示列向量(; 为行分隔,见于matlab/octave中使用) 这里w表示weight,权重的意思,表示对应的属性在预测结果的权重,这个很好理解,权重越大,对于结果的影响越大;更一般化的表示是theta(Andrew ng的课程就是用theta),是线性模型的参数,用于计算结果。 那么通常的线性回归,就变成了如何求得变量参数的问题,根据求得的参数,我们可以对新的输入来计算预测的值。(也可以用于对训练数据计算模型的准确度) 通俗的理解:x(i)就是一个个属性(例如西瓜书中的色泽,根蒂;Andrew ng示例中的房屋面积,卧室数量等),theta(或者w/b),就是对应属性的参数(或者权重),我们根据已有数据集来求得属性的参数(相当于求得函数的参数),然后根据模型来对于新的输入或者旧的输入来进行预测(或者评估)。 如何进行线性回归?解析解法(公式法)对于数据集D,我们需要根据每组输入(x, y)来计算出线性模型的参数值,那么如何计算?  也就是说我们尽量使得f(xi)接近于yi,那么问题来了,我们如何衡量二者的差别?常用的方法是均方误差,也就是(均方误差的几何意义就是欧氏距离,具体的说明可以搜索知乎中的解释) 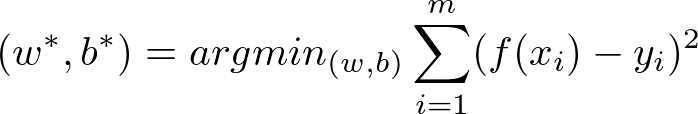 这里的arg min是指后面的表达式值最小时的(w, b)取值。 事实上这就是大名鼎鼎的最小二乘法 (least square method),关于这个算法的背后还有发明权争论(撕逼)的过程,有兴趣可以自行搜索阅读。 那么上面的公式我们如何求得参数w,b呢?于是我们又需要一些微积分(calculus)的知识。(插一句:机器学习为什么很多人抱着极大的热情来开始,又很快灰头土脸地离开,大致就是因为这是一个需要较多,不是较深,数学知识的领域,所以不需要灰心,而是赖着性子,我们继续学习和理解)。 这里  E是关于(w, b)的凸函数(哈哈,又来了个新的fancy word,简单理解为Andrew ng说的boat shape的函数,也就是有一个最小值),只有一个最小值,而E在最小值时的(w, b)就是我们所要求的参数值,关于凸函数的准确定义可以参考我们大学的高数课程(还记得吗?),周志华西瓜书p54旁注有说明。 对于凸函数E关于w,b导数都为零时,就得到了最优解。 E对w求导:  E对b求导:  上面我自己进行了推到(当然这是最简单的部分求导,主要就是平方展开),最终令上面的2个导数为0,即可得到w,b的求解公式:   其中  是x的平均值。 以上是对于输入属性为1个的讨论 对于多个属性的讨论,通常这时就引入了矩阵表示(头又变大,微积分已经早已忘记,线性几何也是啊!),矩阵表示可以很简洁地表示出公式,例如 f(xi) = wTxi + b 将b作为w的一个参数(Andrew ng的课程中都是用theta来表示),那么  然后对w(hat)求导就可以得到w矩阵的解: 上面这个公式就是Andrew ng给出的解析解(也就是不用梯度下降的算法),当时Andrew ng一笔带过没有给出求解过程,周志华老师p55有简单的求解过程。 这里面存在一个问题就是矩阵的逆是否存在的问题(非满秩矩阵非正定矩阵时,头好大哦,没听过,查查线代的书吧),如果不存在如何处理?Andrew ng提到了2种方法:减少属性个数(d),正则化(regularization,这个后续有机会可以再写一篇)。这就像解方程,等式个数少于未知数个数时,我们就会解出多组解,上面提到的减少属性个数就是减少未知数个数。 上面说的都是解析解(也就是直接根据公式来计算,相比于下面介绍的逼近法),下面再说说梯度下降(Gradient Descent)大法。 梯度下降(Gradient Descent) 逼近法首先什么是梯度,可以参考下面这张slide(说的严谨而清晰): 简单地说,我们需要沿着梯度下降的方向找到一个收敛的参数值,Andrew ng给出的算法如下: repeat until converge { } 其中alpha是learning rate, 是用来控制下降每步的距离(太小收敛会很慢,太大则可能跳过最优点),Andrew ng提到了按照对数的方法来选择,例如0.1, 0.03, 0.01, 0.003, etc. 其中的J函数是所谓的cost function(loss function),同样在数学、统计学中有大量的应用,是衡量我们的预测函数f(x)精度的函数,同样我们的目标是最小化J。 注意到其中的参数1/2m,这个参数是可以简化部分求导(消掉2m)。除了参数外,其它部分与解析解部分是完全相同的(事实上,解析解部分的公式也是cost function)。这里的参数是不重要的,因为alpha的选择可以对冲掉。 这个过程可以写程序来完成,具体可以做下Andrew ng的相应部分练习题,完成的过程还是很有意思的,也是不断加深对于梯度下降方法的理解。 注意上面的theta和解析解部分的w,b是一样的(只是换了下字母)。 如何选择那么两种方法(解析解和逼近法)如何选择,解析解好处是显而易见的,例如无需选择learning rate alpha,无需循环,坏处是要有复杂的矩阵运算(转置矩阵,逆矩阵等),复杂度比较高O(n^3),相较而言,梯度下降则是O(d*n^2) Andrew ng提到n10000则可以用梯度下降。当然这不是必然的,我们需要理解为什么不选择解析解,主要是我们的计算机太慢(复杂度太高导致时间过长),随着计算机越来越快,这个经验值可以调整。 为什么进行线性回归?周志华老师提到的西瓜判别,Andrew ng提到的房价预测,都是很好的应用。线性回归鉴于其简单易用,易理解(注意上面提到的权重的理解),所以得到了很广泛的应用,在某些场景下或许有优于其它复杂方法的表现。 另外,随着机器学习的发展,近期出现的explainable AI(也就是不只要预测出结果,还有给出预测的原因解释),而线性回归方法则很符合explainable的要求。(另外决策树也很explainable) 最后Andrew ng在讲完线性回归后突然发出了如下的感慨: 95%的硅谷做AI的engineer都不懂线性回归,而当你懂了线性回归后,你就超过了大多数硅谷搞AI的人,可以去申请Offer了。 很夸张甚至励志是吧?但是你要记得他录视频是在2011年10月左右(source: 演示的电脑),6年过去了,懂个线性回归显然不够了,所以我们还是要继续学习其它的ML知识,譬如下一篇对数几率回归(logistic regression #2 ) 参考资料周志华 《机器学习》Andrew ng: Machine Learning in CourseraLinear regressionconvert latex equations to images latex转换为图片(markdown不支持公式)科学松鼠会 " 正态分布的前世今生(上)Gradient descenthttp://math.fudan.edu.cn/gdsx/KEJIAN/方向导数和梯度.pdfLoss function - Wikipediahttp://www.darpa.mil/program/explainable-artificial-intelligence |




【本文地址】